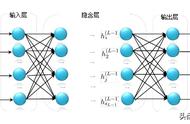
照例先上百度百科:BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之一。
有几个关键词:多层、神经网络、误差、反向传播。
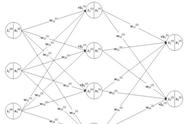
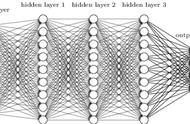
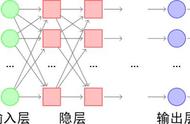
多层神经网络关于多层神经网络,上次聊过,可以简单地理解为多层次神经元的堆砌,组成网状结构。
如果把不同的AI算法当做一个黑盒,神经网络这个黑盒还是可以简单看作一个数据映射,把输入x映射成不同的标签y,这一点跟常规机器学习算法是类似的。
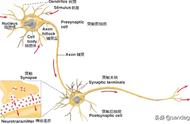
不同点在于,常规的机器学习这个黑盒,内部构造非常复杂,有各种不算的算法,甚至还要对输入进行特征工程等,而神经网络这个黑盒的构造非常简单,把海量线性神经元通过正向和反向链接起来即可,层次结构非常深。
还是用例子类比一下,两者的关系特别像大型机与Hadoop网络。比如一个业务场景对机器的性能要求非常高,大型机的解决思路是人挡*人佛挡*佛,缺啥补啥,内存不够加内存,cpu不够加cpu,操作系统不支持升级操作系统,所以这个思路造出来的是一个巨型机器,也能满足大部分业务场景。但这个思路有两个问题,第一是价格昂贵,第二是性能依然有天花板,不适合普通互联网场景,因为互联网公司没有那么有钱,而且他的需求场景可以说是无限的,比如天猫双11的抢购场景,12306的抢票场景,都很难想象用大型机支持。于是Hadoop闪亮登场了,思路是用一大堆pc机构成一个巨大的网络,解决巨大的问题,性能不够就加机器,存储不够加机器,再不够再加。这个方案的主要难点是如何让这一大堆机器像一台机器一样运转,而且可以平滑的增加机器提升性能。这个思想像极了多层神经网络,智能不够深度来凑,不需要再考虑机器学习那些“琳琅满目”的数学公式、特征工程,一切都交给深度解决,只要训练数据足够,深度足够,总能训练出优秀的模型。
当然,说了这么多,只是一个类比,深度学习发展了这么久,其实内部结构也在复杂化,同时也存在各种问题,但整体结构还是简单的。
误差反向传播BP神经网络训练的还是误差,或者叫损失函数,这与机器学习是一样的。
区别在于,由于神经元的构造非常简单,就是简单的线性逻辑回归 激活函数,所以BP神经网络的训练过程,完全可以用简单粗暴的梯度下降解决,误差可以通过反向传播,逐步优化参数,进而一步一步迭代的减小误差。
基于求导的链式法则,与多层神经网络的梯度下降完美结合,让BP神经网络的训练过程,无论深度有多少层,都可以用粗暴的算力叠加来解决。

我觉得知识学习有两个关键点,一是知识背后的道理,二是例子说明,其实例子也是辅助说明道理的,如果能把这两个事情搞明白,其他都是浮云,搞明白只是时间问题。有时候一个事情怎么都学不会,看公式看算法都不知所云,原因就是其实还没搞清楚背后的逻辑,直接去看前面的东西,肯定一头雾水。
所以我一直在努力的把背后的逻辑搞明白,先把底层基础构建起来,后面的就水到渠成了。
注:
- 大道至简,坚信复杂的理论背后,都有一个简单的道理。
- 5分钟原则,知识碎片化,一篇小文能讲清一个事儿就满足了。