分布式存储系统本身对数据分布有三个基本诉求,而Ceph的数据分布算法机制则满足了分布式存储所要求的这三个基本诉求,那么这是如何实现的?本文将为你解析 Ceph 的数据分布算法。
1. 引言数据分布是分布式存储系统的要解决的首要问题,在分布式存储系统当中,最核心也是最基本的要求就是数据的分布算法或者规则能够解决以下几个问题:
(1) 数据负载均衡:数据能够均匀地分布在磁盘容量不等的存储节点;
(2) 故障隔离:保障不同的数据副本分布于不同的故障隔离域;
(3) 节点变动与数据迁移:正常节点上的迁移影响达到最小,数据量达到最少。
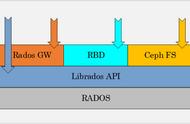
很多分布式存储系统都会用到一致性哈希算法来支撑其数据的均衡分布。例如在Aamzon的Dyanmo键值存储系统,OpenStack的Swift对象存储系统。而Ceph的数据分布主要是靠哈希和CRUSH算法支撑的,而CRUSH算法又是其核心算法。
2. Object_PG映射算法2.1 映射过程
从客户端维度看Object-PG的过程,需要经过两个关键步骤:
(1)File —> Object:将文件按照固定粒度大小(2M/4M)进行切分,得到对象(Obj-ID);
(2)Object —> PG:通过哈希算法HASH(Obj-ID) % PG_Number,得到PG(PG-ID)。
首先,通过接口调用保障文件可以平均切分为多个2/4M的对象以及对象的有序标识号。然后,通过哈希算法将有序序列分散,经过取余计算将对象均匀分布在逻辑分区内的PG上。
2.2 PG的价值
我们知道,在Ceph中的Pool& PG(Placement Group)其实是逻辑概念,它是把Ceph的整个存储空间用Pool划为若干逻辑的分区,每一个Pool又是由很多个PG组成,每一个PG对应于唯一Object的数据分布控制,它对应于一个OSD的故障隔离组(1Primary-OSD & 2Replic-OSD)。结合图2.2所示,我们可以清晰看到PG在数据分布当中的首个核心价值。

图2.2 FIle_PG 数据映射分布图示
结合图2.2,我们回过头来看File_PG的算法过程:
首先,从File到Object的切分过程,会得到一组有序标识的Objects;然后经过哈希并取余的算法( HASH(Obj-ID) % PG_Number )得到Object对应的PG。Pool和PG的组成结构是个虚拟的概念,在物理节点经常变动的整个过程当中,每一个Pool之内的PG数量是不会发生变化的。不难理解,随着写入文件数量规模越来越大,被切分的一个个有序Object组会均匀分布在图2.2 Pool当中的各个PG上,而且Object-ID的取值范围远远超过PG_Number,这样就会保障同一个文件当中Object在整个Pool分布的分散性特点。
虽然Object-PG并不代表数据的物理分布达到了应有的均衡性,但是最起码为后续PG-OSD映射的均衡性奠定了基础。读到这里,或许有人会有疑问“ 为什么不直接完成Object-OSD的映射,这样不是更直接,性能更好么? ”。
那么,顺着这个疑问的思路,我们不妨把算法改变为( HASH(Obj-ID) % OSD_Number ),这里的取余被除数由PG_Number变成了OSD_Number,逻辑节点变成了物理节点,不变的因素变成了经常会发生变化的因素(故障&扩容)。一旦发生这种变化,之前存储的所有数据的计算结果大概率发生变化,这样的变化会带来大规模的数据迁移。这显然是与分布式系统数据分布的基本诉求点是相悖的。
因此,无论是采用哈希一致性算法还是采用其他数据分布算法,中间的虚拟对象是必要的。
3. PG_OSD映射算法3.1 cluster_Map
Ceph的cluster Map 包含的几个主要map分别是 Monitor map、OSD map、CRUSH map、PG map。这些 cluster map 将有助于知晓集群的状态和配置。接下来分别看看这些Map当中都包含了哪些基础的信息。
(1) Monitor Map:它包含Monitor基本信息,例如集群ID、monitor节点信息、IP地址和端口号、配置版本、时间戳等相关信息。
(2) OSD Map:一方面是OSD自身的信息(节点、容量、状态、权重等);另外一方面是存储池相关的信息(存储池名称、ID、类型、副本级别、PGs)。
(3) PG Map:一方面是PG自身信息(ID、版本、时间戳、OSD map的最新版本号、容量);另外一方面是对象信息(数量、状态、时间戳、OSD sets等)。
(4) CRUSH Map:它保存的信息包括集群设备列表、bucket列表、故障域(failure domain)分层结构、保存数据时用到的为故障域定义的规则(rules)等。
PG_OSD的映射过程主要依赖于PG Map & CRUSH Map。接下来我们来看看CRUSH Map究竟是一个什么样的数据结构。将代码的结构化逻辑提取出来之后,如下所示:

这里面,“device”即OSD实例,“types”={root、region、datacenter、room、pod、pdu、row、rack、chassis、host、osd}。从“types”可选项的数据结构不难看出它是一个分层的树形结构,从上到下包含了根、区域、数据中心、机房...、主机、磁盘系列分层对象。如图3.1.2所示:

图3.1 CRUSH Map说明示意图
图中,黑色的节点我们称之为Bucket,绿色的节点称之为leaf,那么“buckets”就保存了一棵具有所有OSD信息的完整的树形结构。