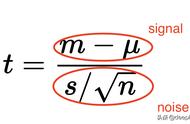注意回归系数的正负要符合理论和实际。截距项的回归系数无论是否通过T检验都没有实际的经济意义。
02 回归系数的标准差
标准误差越大,回归系数的估计值越不可靠,这可以通过T值的计算公式可知(自查)。
03 T检验T值检验回归系数是否等于某一特定值,在回归方程中这一特定值为0,因此T值=回归系数/回归系数的标准误差,因此T值的正负应该与回归系数的正负一致,回归系数的标准误差越大,T值越小,回归系数的估计值越不可靠,越接近于0。另外,回归系数的绝对值越大,T值的绝对值越大。
04 P值P值为理论T值超越样本T值的概率,应该联系显著性水平α相比,α表示原假设成立的前提下,理论T值超过样本T值的概率,当P值<α值,说明这种结果实际出现的概率的概率比在原假设成立的前提下这种结果出现的可能性还小但它偏偏出现了,因此拒绝接受原假设。
05 可决系数(R-squared)都知道可决系数表示解释变量对被解释变量的解释贡献,其实质就是看(y尖-y均)与(y=y均)的一致程度。y尖为y的估计值,y均为y的总体均值。
06 调整后的可决系数即经自由度修正后的可决系数,从计算公式可知调整后的可决系数小于可决系数,并且可决系数可能为负,此时说明模型极不可靠。
07 回归残差的标准误残差的经自由度修正后的标准差,OLS的实质其实就是使得均方差最小化,而均方差与此的区别就是没有经过自由度修正。
08 对数似然估计函数值首先,理解极大似然估计法。极大似然估计法虽然没有OLS运用广泛,但它是一个具有更强理论性质的点估计方法。极大似然估计的出发点是已知被观测现象的分布,但不知道其参数。极大似然法用得到观测值(样本)最高概率(离散分布以概率聚集函数表示,连续分布以概率密度函数表示。因为要使得样本中所有样本点都出现,假定抽样是随机的则各个样本点的是独立同分布的,所以最后总的概率表现为概率聚集函数或者概率密度函数的连乘形式,称之为似然函数。要取最大概率,即将似然函数对未知参数求导令导数等于0即可获得极大似然函数。一般为简化函数的处理过程都会对似然函数进行对数化处理,这样最后得到的极大似然函数就称之为对数极大似然函数)的那些参数的值来估计该分布的参数,从而提供一种用于估计刻画一个分布的一组参数的方法。
其次,理解对数似然估计函数值。对数似然估计函数值一般取负值,实际值(不是绝对值)越大越好。第一,基本推理。对于似然函数,如果是离散分布,最后得到的数值直接就是概率,取值区间为0-1,对数化之后的值就是负数了;如果是连续变量,因为概率密度函数的取值区间并不局限于0-1,所以最后得到的似然函数值不是概率而只是概率密度函数值,这样对数化之后的正负就不确定了。第二,Eviews的计算公式解释。公式值的大小关键取之于残差平方和(以及样本容量),只有当残差平方和与样本容量的比之很小时,括号内的值才可能为负,从而公式值为正,这时说明参数拟合效度很高;反之公式值为负,但其绝对值越小表示残差平方和越小,因而参数拟合效度越高。
09 DW检验值DW统计量用于检验序列的自相关,公式就是测度残差序列与残差的滞后一期序列之间的差异大小,经过推导可以得出DW值与两者相关系数的等式关系,因而很容易判断。DW值的取值区间为0-4,当DW值很小时(大致<1)表明序列可能存在正自相关;当DW值很大时(大致>3)表明序列可能存在负自相关;当DW值在2附近时(大致在1.5到2.5之间)表明序列无自相关;其余的取值区间表明无法确定序列是否存在自相关。当然,DW具体的临界值还需要根据样本容量和解释变量的个数通过查表来确定。
DW值并不是一个很适用的检验手段,因为它存在苛刻的假设条件:解释变量为非随机的;随机扰动项为一阶自回归形式;解释变量不能包含滞后的被解释变量;必须有截距项;数据无缺失值。当然,可以通过DW-h检验来检验包含滞后被解释变量作为解释变量的序列是否存在自相关。h统计量与滞后被解释变量的回归系数的方差呈正相关关系,可以消除其影响。
10 被解释变量的样本均值被解释变量的样本均值
(Mean Dependent Var)
11 被解释变量的样本标准误差被解释变量的样本标准误差(S.D.Dependent Var)
12 赤池信息准则(AIC)AIC和SC在时间序列分析过程中的滞后阶数确定过程中非常重要,一般是越小越好。
一般理解:根据AIC的计算公式(-2*L/N 2*k/N,L为对数似然估计函数值,k为滞后阶数,N为样本容量)可知:当滞后阶数小时,2*k/N小,但因为模型的模拟效果会比较差所以L(负值)会比较小,加上负号之后则变得较大,因此最后的AIC有可能较大;当滞后阶数大时,模型的模拟效果会比较好所以L(负值)会比较大,加上负号之后则变得较小,但是2*k/N过大(损失自由度的代价),因此最后的AIC也有可能较大。综上,AIC较小意味着滞后阶数较为合适。
13 施瓦茨信息准则(SC)与AIC没有任何本质区别,只是加入样本容量的对数值以修正损失自由度的代价。
14 F统计量(F-statistic)F统计量考量的是所有解释变量整体的显著性,所以F检验通过并不代表每个解释变量的t值都通过检验。当然,对于一元线性回归,T检验与F检验是等价的。
15 prob(F-statistic)F统计量的P值,一切的P值都是同样的实质意义。