虽然数据库技术和大数据已经广泛使用,公司打造内部数据平台时,对基于关系型数据库,或者是格式标准的文件,例如JSON,XML,CSV等数据一体化都相对容易。因为这些数据载体标准,变化可控,易于分辨,且都有成熟的工具/包,来辅助抽取和解析。
生产生活中,Excel文件仍然是常见数据承载媒介。公司运作的过程中,也会产生很多有价值的数据,存在易于阅读和方便传播的Excel文件中。Excel文件没有统一的格式,数据编排方式完全依赖个人的习惯和偏好,不可能被标准化。
当想把这些数据落地存储为公司的数据资产时,很难用一套通用程序来处理。虽然现在满天飞各种数据中台类产品,但只能解决企业内标准化数据源(90%都是关系型数据库)的整合问题,几乎不涉及存储在excel中的数据,导致这些文件中的数据都是游离在公司数据体系之外的。
适用对象哪些情景,或者说工作环境中有对Excel数据治理的需求呢?总结了一下大概分成四类:
1. 工作业务流程接触很多excel中的时序数据。这些文件可能是内部产生的,也可能是外部产生的。主要依靠人阅读的方式消费文件,需要提升效率;
2. 公司产生很多有价值的数据,都在excel中,想把它数字资产化;
3. 公司有一定的IT基础,数据架构很完善,数据中台基本都已成型,想打通零散的Excel线下数据;
4. 数据公司。汇聚各类细分数据源的Excel文件,生产自己的EDB指标;
痛点要完成上面的目标,有个痛点一定绕不过去,就是自由格式的Excel文件解析。 Excel传统上一般有3种处理方式:
1. 格式简单/标准
标准的二维矩阵形式,可用ETL工具直接导入。比如kettle,指定sheet名,数据起始的行列,preview一下数据,自动识别出列的格式,生成二维表。
直接用Python中的pandas读取也都很容易;或者Navicat都可以把直接导入数据库表中。
2. 格式复杂
有两种处理方式:
2.1 定义一个中间标准模板态(一个模板Excel)。把非标准形式的excel文件手工往这个形式转换,后者再用程序批量处理;
2.2 对每个Excel文件的每个sheet,写单独的程序去解析;
即使通过上面几种方式实现了,当文件中的数据内容、排版方式发生变化时,比如数据中间插入了一行或者一列,某个sheet改名了,单元格的指标名称改了等等,靠人或者程序去识别这类变化,都非常困难;文件改变后,还要对(手工)转换过程或者代码做相应的修改和测试,也很耗时。
识别文件内容变化,以及根据变化迅速调整处理逻辑,是解析的难点。当然,更为重要的,是用低成本(人、时间)迅速响应数据格式的变化。
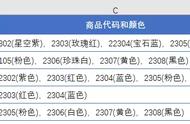
格式自由Excel格式因人而异,没有标准,想怎么弄就怎么弄。比如:

季频和年频数据混合,且都有预测值。A列的含义丰富,既有分类,又有不同指标,还有同比

6月和7月每个日期下面有3个指标;8月之后,每个日期就只有2个指标了;日期是合并单元格;

水平 垂直方向组合才构成完整的日期;A列看到的值和真实的值不同;