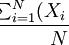说过了,很多人都会想到最近非常流行的两句调侃 “被平均” 和 “拖后腿” 。既然我们说了均数是非常好的代表总体的一个指标,那这种感觉是怎么来的呢?直觉错了么?除了故意抬杠,这个直觉是有一定道理。
相信大部分人听说过 “正态分布”。这个正态分布的英文名有两个,一个是高斯分布,为的是纪念它的发现者数学天才高斯。而另外一个呢,就是 Normal Distribution,也就是 “正常分布”。为什么这么说呢,因为这个分布在真实世界里实在是太常见了(和斐波那契数列差不多了)。这里我们不展开正态分布的事,以后会讲。现在我们只要知道正态分布很常见。在正态分布中大部分的数据(如果算平均薪水的话,就是大部分人的薪水的数值)是集中在整体数据的平均数的附近的。换句话讲,就是这个 “均数” 可以代表大部分数据。这个就是我们在统计意义上,对“平均”这个事情的信心来源,通常来说 “均数” 代表了大多数,而且这才叫 “正常” 。
好了,那么问题来了,既然只是“集中在平均数附近”,就说明并不是所有数据都正好等于均数(废话)。超过大家没意见,少了就有人觉得被平均了。这里就可以给出一个概念,离均差。顾名思义,就是每个数据离开均数的差距,公式就是做减法。若 代表数据,表示均数,那么离均差就是。
一个数据如此,那全部数据呢?最简单的想法就是,把离均差都加起来呗。问题又来了,稍微算一下就知道离均差有正有负。如果简单地加总,那么答案永远是零,就失去的比较不同总体(比如上海和北京的平均薪水)的意义,零等于零么?
这里需要进行一下数学上的处理,把离均差先平方以后再加总。一来是方便,平方一般都会算的;另外呢,平方也不影响单调性。通俗地说,就是3比2大,那么3的平方9也比2的平方4大,这样就不影响比较了。于是公式就成了:

问题又来了。不同的总体拥有的数据量是不同的,比如北京和上海的在职人数不同,那么人数多的总体就有可能怎么都比人数少的那个大。北京上海还不明显,你要北京和某四线城市比呢?对吧。这时,我们肯定会很自然的想,那么再除以这个城市人数不就可以了?对的,所以式子就变成了:

这里直接把方差的希腊字母放上去了,因为这个公式就是方差的定义公式。通过考察每个数据离开均数的差距,我们可以描述这个“被研究的总体”到底有多少人是“被平均”了,统计上说就是一个数据集的离散程度有多少。
好了,问题又来了.....(怎么这么多问题![泪奔])
平方仅仅是个数学处理,在现实生活中一般没有啥意义,薪水的平方啥意思?又不能领了薪水先平方下再去花[呲牙]。所以,在统计指导意义上,还是再把方差求平方根。当然一般只取正值,或者叫绝对值,但实际上表达的是正负都可以。这个平方根就是标准差(sigma)。

如果有人对前几年大流行的精益管理还有印象的话,这个西格玛就是6西格玛里的西格玛。精益的 six sigma 就是用到了正态分布的双侧检验,以后有机会再讨论。

6σ Analysis
关注采客,下一次我们来讨论参数估计。如需更多支持服务,敬请留言~
采客,身边的创业智库![呲牙]