官方定义:链表是一种物理存储结构上非连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
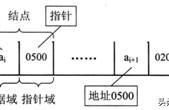
用一张图表示如下:

可以这样描述:结点散落的分布在内存区域中,每个结点地址保存在前一个结点的指针域中,同时该结点的指针域又保存下一个结点的地址。
指向第一个结点的指针叫做头指针
- 链表的优点是相对于顺序表而言的,由于顺序表一次开辟一大片空间,而且增容时也会造成一定空间的浪费。所以链表可以按需索取,同时其插入和删除也十分方便
- 当然链表也是有缺点的,最大的缺点在于它不能像顺序表那样随机访问,就拿最普通的单链表而言,要想找到它最后一个结点,那么必须完整访问前n-1个结点,类似于按图索骥。
链表的分类很多,带头结点,不带头结点,单链表,双链表等等。但是我们最常用的就是以下两种

和前面一样,也是三个文件

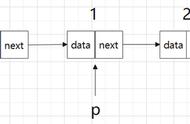
对比顺序表,顺序表就像是许多相同的结构体,依次排列,虽然这样说不准确,但是有助于理解。那么对于链表来说,可以比喻为把顺序表中的每个结点“打散”,分散于内存中,以前对于顺序表来说,整个结点全放数据就很OK,那是因为下一个数据一定在该结点后面,不用担心找不见。但是对于链表来说,把它“打散”之后,就存在一个问题,如何去找下一个元素?就像一条链子,其中一环断了,整个也就断了。也就是说,对于链表,它的结点内不能只存放数据,还必须腾出一定空间来放一个指针,这个指针指向下一个结点
通过上述描述,可以定义单链表中每个结点的结构体如下
一个单链表一定会有一个头指针,头指针一定指向第一个结点,如果它指向的第一个结点没有存放数据(这个结点也经常叫做哨兵结点),这样的链表称为带头结点的链表,相反如果它指向的第一个结点存放了数据,这样的链表称为不带头结点的链表(不带头结点的链表是oj题的“常客”)