市值风云APP原创作品 欢迎转发,转载需授权

作者 | 熊本熊(实习生)
编辑 | 小鲨鱼
上市公司造假的手段,主要可以分为三类:
其一,收入类造假,如伪造合同虚构收入的万福生科;
其二,成本费用类造假,如通过少计成本虚增利润的三峡新材;
其三,关联交易造假,如隐瞒与关联方之间的交易,导致利润总额虚增的康欣新材。
在大A股这充满诱惑的市场,遍地都是娇嫩的韭菜,只要通过会计分录,简简单单便能割走大把钱财,让揣着镰刀的老板,如何按耐得住心中的悸动呢。
而对于财务造假的识别,一直是一个难题,每一家上市公司看起来都是那么眉清目秀婀娜多姿,没有谁脸上写着“造假”两个字。

别说普通的投资者,就是在资本市场浸淫多年且具备专业财务技能的业内人士,也很难识破财务舞弊。
在互联网技术突飞猛进的当今社会,风云君曾想是否可以利用互联网技术来提高财务舞弊识别效率,甚至开发一种简单实用的财务舞弊辅助识别工具?
一、本福特定律本福特定律,是一个有关于首位数字在数值数据集的频率分布,此定律已经存在很长的一段时间,但到了最近几年才被频繁地讨论和使用。
本福特定律命名来源于20世纪的英国科学家本福特,他使用的前提限制为,数据必须为自然数据,所以人为制造的数据,像手机号码、身分证字号都不适用这个定律。
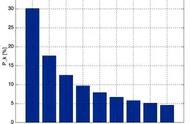
本福特定律指出在这些自然数据中,如信用卡付费帐单、财务报表等,第一个首位数字1(例如:1 ,123,1234)的出现次数约为30.1%,首位数字是2的比例约为17.6%,后面数字出现的机率将逐渐变小,到首位字母为9时,数字出现机率已经小于5%。
本福特定律:P(d)=

这个结论与常人的直观结论不同,一般来说我们会认为1~9每个数字,出现的机率皆为1/9,但本福特定律指出,在自然数据下,首字母的分布,并不是这样的。
据说本福特是在翻对数表时发现这个定律的,像图书馆的书一样,前面几页的颜色总是特别深,越到后面颜色越浅,书页越新,因而让本福特想到,是不是1为首字母的数会是最多的呢,从而得出这个定律。
二、手把手教你用python建模接下来科普点技术。
大A股3000多家上市公司,算上每年IPO的企业,若是一家一家用excel建模,那得到何年何月才能做完呢?
俗话说授人以鱼不如授人以渔,今天风云君便手把手教大家,如何用python建模,来检验上市公司报表的首位字母是否满足本福特定律。
ps:对于不想学的老板们,看到这边就可以直接跳到最下面的留言区,只要阅读量过万,留言区便会将源码奉上。
步骤一:安装python3
步骤二:安装这次所需要的库