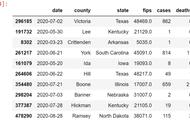
Pandas中的read_csv()函数可以从CSV文件中读取数据并创建DataFrame对象。CSV(Comma-Separated Values)是一种常见的用于存储数据的文本文件格式,其中每行表示一条记录,每个字段由逗号分隔。
以下是一些常见的read_csv()函数参数:
filepath_or_buffer: CSV文件的路径或URL,或者是包含CSV数据的字符串或文件对象。可以是本地文件路径或者远程文件的URL,也可以是类似于io.StringIO的内存文件对象。
sep: CSV文件中字段之间的分隔符,默认是逗号(',')。也可以指定制表符('\t')、分号(';')等其他分隔符。
header: CSV文件的列名行在哪一行,默认是第一行。可以是整数行号,也可以是列表形式的行号。
index_col: 将哪一列作为行索引,可以是列名、列号或者一列列标签组成的列表。如果不指定该参数,则使用默认的整数行号作为行索引。
usecols: 指定哪些列需要被读取,默认是读取所有列。可以是列名列表、列号列表或者是一个函数,函数会接受列名作为参数,返回True或False。
dtype: 指定每一列的数据类型,可以是Python的数据类型、NumPy的数据类型或者Pandas的数据类型。例如:{'column1': int, 'column2': 'float64'}
na_values: 指定哪些字符串表示缺失值,默认是['', 'NA', 'NaN']。也可以指定其他字符串或列表。
skiprows: 跳过哪些行,可以是行号列表、函数或者整数值。默认值为None,表示不跳过任何行。
encoding: 指定CSV文件的编码方式,默认是'utf-8'。如果CSV文件采用其他编码方式,需要指定该参数。
下面是一个使用read_csv()函数从CSV文件中读取数据的示例:
import pandas as pd
# 从CSV文件中读取数据
df = pd.read_csv('data.csv', header=0, index_col=0)
# 打印DataFrame对象的前5行
print(df.head())
这个示例从名为data.csv的文件中读取数据,并将第一行作为列名,第一列作为行索引。然后打印DataFrame对象的前5行。