作者丨Pradeep Menon
原文丨https://towardsdatascience.com/data-science-simplified-hypothesis-testing-56e180ef2f71
译者丨TalkingData 张永超
在此系列之前的文章(见文末)中,已经讨论了关于统计学习的关键概念和假设验证相关内容。在本篇内容中,将进入线性回归模型的讨论。
在开始之前,回顾一下之前统计学习中比较重要的几个关键点:
自变量和因变量:
在统计学习的背景下,有两种类型的数据:
- 自变量:可以直接控制的数据。
- 因变量:无法直接控制的数据。
无法控制的数据,即因变量需要预测或估计。
模型:
模型本质上就是一个转换引擎,主要的作用就是找到自变量和因变量之间的关系函数。
参数:
参数是添加到模型中用于估计输出的一部分。
基本概念线性回归模型提供了一个监督学习的简单方法。它们简单而有效。
但是,到底什么是线性?
线性意味着:数据点排列在或者沿着一条直线或者接近直线的线排列。线性表明,因变量和自变量之间的关系可以用直接表示。
回顾高中时的数学课程,一条直线的方程式是什么呢?
y = mx c
线性回归只不过是这个简单方程的表现。
上述公式中:
- y是因变量,是需要估计或者预测的变量
- x是自变量,是可控的变量,在这里属于输入变量
- m是斜率,体现了直线的倾斜程度,一般使用符号β表示
- c是截距,当x为0时,确定y值的一个常数
线性回归模型并不是完美的,它试图以直接来逼近自变量和因变量之间的关系。而近似总会导致错误,并且一些错误是无法避免的,是问题性质本身所固有的,这些错误无法消除,称之为不可简化的错误,真正的关系中,总是具有一定的噪声项,并且是任何模型无法减少的。
上述直接公式因此可以重写为:

- β0和β1是代表截距和斜率的两个未知常数。他们是参数。
- ε是误差项。
简述
下面通过一个例子来说明线性回归模型的术语和工作原理。
费尔南多是一名数据科学家,他想要买一辆车。他想估计或者预测他最终必须支付的汽车价格。正好他有一个朋友在一家汽车经销商上班,费尔南多向这位朋友咨询了各种其他汽车的价格以及汽车的一些特点,他的朋友向他提供了如下的一些信息:

- make: 车辆品牌
- fuelType:所使用的动力燃料
- nDoor:车门数量
- engineSize:发动机大小(马力)
- price:最终的价格
首先,费尔南多希望评估他是否可以根据发动机大小预测汽车价格。第一组分析旨在回答以下问题:
- 汽车价格与发动机大小有关吗?
- 这种关系有多强?
- 关系是线性的吗?
- 我们可以根据发动机大小预测/估算汽车价格吗?
费尔南多进行了相关分析,相关性是衡量两个变量相关的程度。它是通过称为相关系数的度量来衡量的,值在0和1之间。
如果相关系数是一个较大的数,例如 0.7 以上的数,则意味着随着一个变量的增加,另一个变量也会增加。也就说,相关系数体现了变量间“同向变化”情况。
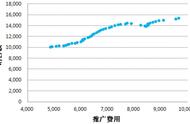
费尔南多做了一些相关性的分析,绘制出了价格与发动机大小之间的关系。
他将数据集分割成了训练和测试两部分,其中75%的数据作为训练使用,剩下的作为测试来用。
他使用了一些统计性软件包构建了一个线性回归模型,该模型本身找到了汽车的价格和发动机大小间的关系,由此创建了一个线性方程。

有了这个模型之后,就可以回答费尔南多想了解的几个问题了:
- 汽车价格与发动机大小有关吗?
- 是的,它们之间是有关系的。
- 这种关系有多强?
- 它们间的相关系数为0.872。是一种很强的关系。
- 关系是线性的吗?
- 存在一条直线可以拟合。一个良好的价格预测可以由发动机大小来决定。
- 我们可以根据发动机大小预测/估算汽车价格吗?
- 可以。
对于价格和发动机大小的关系显而易见,其实这个模型的最终表达式也很简单,如下:
price = β0 β1 x engine size
模型构建与解释模型
在上述内容中,原始数据集按照一定的比例进行了分割,产生训练集和测试集两大部分,训练集被用于学习或者找规律,最终创建模型,测试集被用于评估模型的性能。
费尔南多将数据集分割成了训练和测试两部分,其中75%的数据作为训练使用,剩下的作为测试来用。他使用了一些统计性软件包构建了一个线性回归模型,该模型本身找到了汽车的价格和发动机大小间的关系,由此创建了一个线性方程。