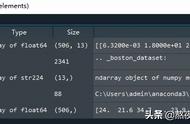
通过从训练数据集上进行学习训练,费尔南多得到了如下的一些结果:

对于最终的模型来说,其估计参数值为:
- β0:-6870.1
- β1:156.9
从而得到线性方程为:
price = -6870.1 156.9 x engine size
解释

该模型最终提供了在特定发动机大小的情况下预测汽车平均价格的方程式,也就意味着:
发动机的大小增加一个单位,将使得汽车的平均价格提高156.9个单位。
评估
模型创建好了,但是模型的稳健性还需要评估。我们如何确定该模型能够预测令人满意的价格?这项评估分两部分完成。首先,测试模型的鲁棒性。其次,评估模型的准确性。
费尔南多首先在训练数据上评估模型,他得到了如下的统计数据:

有很多的统计数据,当前仅关注红色框标注的部分,在假设检验章节中有过讨论,使用假设检验评估模型的稳健性。
H0 和 Ha需要被首先定义,如下:
- H0(空假设):x 和 y 之间没有任何关系,即发动机的大小和车辆价格没有关系;
- Ha(替代假设):x 和 y 之间存在某种关系,即发动机大小和车辆价格之间存在关系。
β1:β1 的值决定了价格和发动机大小之间的关系。如果 β1 = 0,则他们之间没有关系,否则存在关系。而从上述得到的参数中可知,β1 = 156.933,说明到价格和发动机大小之间存在某种关系。
t-stat:t-stat值是系数估计值(β1)远离零点的标准差。其值越远离零越强化价格和发动机大小间的关系,从上述参数中可以看到t-stat是21.09。
p-value:p值是一个概率值。它表示在空假设为真的情况下得到给定t-statistics的机会。如果p值小,例如<0.0001,这意味着这是偶然的并且没有关系的概率非常低。在这种情况下,p值很小。这意味着价格和引擎之间的关系并非偶然。
通过这些指标,可以得到的结论是:空假设完全不存在,并且接受替代假设。车辆的价格和发动机大小之间存在着稳定的关系。
这种关系已经确定,但是其精度如何呢?为了能够感受模型的准确度,一个名为R-squared或者决定系数的度量非常重要。
R平方或确定系数:为了理解这些指标,首先将其分解其组成部分。