从上图中,我们看到所有数据点都靠近45度线,因此我们可以得出结论,它遵循正态分布。
方差假设检验的同质性检查应针对分类变量的每个级别检查方差假设的同质性。我们可以使用Levene检验来检验组之间的均等方差。
w, pvalue = stats.bartlett(newDf['Count'][newDf['density_Group']=='Dense1'], newDf['Count'][newDf['density_Group']=='Dense2']
, newDf['Count'][newDf['density_Group']=='Dense3'], newDf['Count'][newDf['density_Group']=='Dense4'])
print(w, pvalue)
## Levene 方差测试
stats.levene(dataNew['Dense1'],dataNew['Dense2'],dataNew['Dense3'],dataNew['Dense4'])
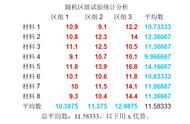
我们发现所有密度组的p值都大于0.05。因此,我们可以得出结论,各组具有相等的方差。
Python中的双向方差分析测试同样,使用相同的数据集,我们将试图了解一个地区或州的密度、人口年龄和日冕病例数量之间是否存在显著关系。因此,我们将根据居住在其中的人口密度绘制每个州的地图。
让我们导入数据并检查是否存在任何数据歧义:
individualDetails=pd.read_csv('./individualDetails.csv',parse_dates=[2])
stateDensity=pd.read_csv('./stateDensity.csv')

从上面的代码片段中,我们可以看到没有感染婴儿的记录。接下来,检查数据中是否缺少值:
individualDetails.isna().sum()
print('Percentage of missing values in age & gender columns respectively :', \
(individualDetails['age'].isna().sum()/individualDetails.shape[0])*100,'%',\
(individualDetails['gender'].isna().sum()/individualDetails.shape[0])*100,'%')
我们发现在年龄和性别栏中分别有超过91%和80%的条目丢失。所以我们需要设计一种方法来估算它们。
在这里,我将以各州的性别中位数和各州的性别中位数估算年龄。因此,我将计算中位数和众数:
ageMedianPerState=individualDetails[~individualDetails['age'].isna()]
ageMedianPerState['age']=ageMedianPerState['age'].astype(str).astype(int)
ageMedianPerState=ageMedianPerState.groupby('State')[['age']].median().reset_index()
ageMedianPerState['age']=ageMedianPerState['age'].apply(lambda x:math.ceil(x))
#通过COVID-19查找每个州的最常感染的性别
genderModePerState=individualDetails.groupby(['State'])['gender'].agg(pd.Series.mode).to_frame().reset_index()
#这没有获得有关总体性别的信息性别
genderModePerState=genderModePerState[genderModePerState['State']!='Arunachal Pradesh']
#现在在年龄和性别栏填充丢失的值
for index,row in individualDetails.iterrows():
if row['State']=='Arunachal Pradesh':
individualDetails.drop([index],inplace=True)
continue
if pd.isnull(row['age']):
individualDetails['age'][index]=list(ageMedianPerState['age'][ageMedianPerState['State']=='West Bengal'].values)[0]
if pd.isnull(row['gender']):
if len(genderModePerState['gender'][genderModePerState['State']==row['State']].values)>0:
individualDetails['gender'][index]=(genderModePerState['gender'][genderModePerState['State']==row['State']].values[0])
现在,让我们合并individualDetails和stateDensity数据帧,为我们创建一个整体数据集:
data = pd.merge(individualDetails,stateDensity,on='State',how='left').reset_index(drop=True)
现在我们可以创建年龄组桶:
data.dropna(subset=['density_Group'],inplace=True)
data.reset_index(drop=True,inplace=True)
合并数据以获得一个数据集,其中每个人都映射了他们的年龄组和各自的州密度组:
patient_Count=data.groupby(['diagnosed_date','density_Group'])[['diagnosed_date']].count().\
rename(columns={'diagnosed_date':'Count'}).reset_index()
data=pd.merge(data,patient_Count,on=['diagnosed_date','density_Group'],how='inner')
newData=data.groupby(['density_Group','age_Group'])['Count'].apply(list).reset_index()
newData.head()
np.random.seed(1234)
AnovaData=pd.DataFrame(columns=['density_Group','age_Group','Count'])
for index,row in newData.iterrows():
count=17
tempDf=pd.DataFrame(index=range(0,count),columns=['density_Group','age_Group','Count'])
tempDf['age_Group']=newData['age_Group'][index]
tempDf['density_Group']=newData['density_Group'][index]
tempDf['Count']=random.sample(list(newData['Count'][index]),count)
AnovaData=pd.concat([AnovaData,tempDf],axis=0)
检查数据中Count列的分布,并使用箱线图方法检查数据中是否存在异常值:
plt.hist(AnovaData['Count'])
plt.show() sns.kdeplot(AnovaData['Count'],cumulative=False,bw=2)

我们发现在我们的数据中有许多异常值。甚至计数变量的分布也不是高斯分布。因此,我们将使用Box-Cox变换方法来处理这种情况:
sns.boxplot(x='age_Group', y='Count',
data=AnovaData,
palette="colorblind")

AnovaData['Count']=AnovaData['Count'].astype(int)
## 数据转换
AnovaData['newCount'],fitted_lambda = stats.boxcox(AnovaData['Count'])
import matplotlib.pyplot as plt
sns.kdeplot(AnovaData['newCount'],cumulative=False,bw=2)
现在让我们使用OLS模型来检验我们的假设:
## 拟合OlS模型-方法1
model2 = ols('newCount ~ C(age_Group) C(density_Group)', AnovaData).fit()
print(f"Overall model F({model2.df_model: },{model2.df_resid: }) = {model2.fvalue: }, p = {model2.f_pvalue: }")
model2.summary()