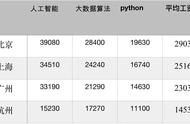
在之前的文章中,我们经常有机会了解扩展如何帮助机器学习模型做出更好的预测。缩放的完成原因很简单,如果特征不在同一范围内,机器学习算法将以不同的方式对待它们。用蹩脚的话来说,如果我们有一个特征的值范围从0-10到另一个0-100,机器学习算法可能会推断出第二个特征比第一个特征更重要,因为它具有更高的值。
我们已经知道,情况并非总是如此。另一方面,期望真实数据处于同一范围内是不现实的。这就是为什么我们使用缩放,将我们的数值特征放入相同的范围。这种数据标准化是许多机器学习算法的共同要求。其中一些甚至要求特征看起来像标准的正态分布数据。有几种方法可以扩展和标准化数据,但在我们通过它们之前,让我们观察一下PalmerPenguins数据集"body_mass_g"的一个特征。
scaled_data = data[['body_mass_g']]
print('Mean:', scaled_data['body_mass_g'].mean())
print('Standard Deviation:', scaled_data['body_mass_g'].std())
Mean: 4199.791570763644
Standard Deviation: 799.9508688401579
此外,请观察此功能的分布:

首先,让我们探讨一下保留分发的缩放技术。
5.1 标准缩放这种类型的缩放会删除均值,并将数据缩放到单位方差。它由以下公式定义:

其中均值是训练样本的均值,std 是训练样本的标准差。理解它的最好方法是在实践中看待它。为此,我们使用SciKit Learn和StandardScaler类:
standard_scaler = StandardScaler()
scaled_data['body_mass_scaled'] = standard_scaler.fit_transform(scaled_data[['body_mass_g']])
print('Mean:', scaled_data['body_mass_scaled'].mean())
print('Standard Deviation:', scaled_data['body_mass_scaled'].std())
Mean: -1.6313481178165566e-16
Standard Deviation: 1.0014609211587777

我们可以看到,数据的原始分布被保留了下来。但是,现在数据在 -3 到 3 的范围内。
5.2 最小-最大缩放(规范化)最流行的缩放技术是规范化(也称为最小-最大规范化和最小-最大缩放)。它将 0 到 1 范围内的所有数据缩放。此技术由以下公式定义: